


A lot of SEO content focuses on ranking well in desired search results. That makes sense because you can’t drive traffic to your site from organic search without ranking well in search results (i.e., the Google index). Plus, you can’t drive leads and sales for your business without driving organic traffic. If you’re a marketing executive, director, manager, etc. this is likely your primary concern.
In order to rank for desired terms, first, you need a presence in the Google index. Once upon a time getting your site into the index was somewhat difficult. “Site submission” was a common service. However, now Google is very good at finding new sites. For example, if you tweeted about your site, sent out a press release or virtually anyone linked to your site, then Google likely knows you exist. But if you’ve tried to drive search traffic you’ve likely run into some variety of Google indexation issues as your site grows.
For non-SEOs (and frequently for SEOs as well) a lot of these issues remain very confusing and frustrating. Virtually every time I walk through an SEO audit with a client there’s at least some confusion about indexation issues, duplicate content, the best way to remove pages from Google’s index, etc.
What to Expect from this Google Index Overview
In this article I’ll try to help a marketing generalist (someone with a basic understanding of SEO who is responsible for driving more traffic to their website but may not be knee-deep in Screaming Frog crawls and link analysis on a day-to-day basis) understand:
- How the Google index works.
- Interpret different index stats or “counts” from Google.com.
- Understand your Google Search Console account.
- Technical fixes for common indexation issues (i.e., not having pages indexed or having pages you don’t want indexed leaking into the index).
Let’s start at the beginning.
How Does the Google Index Work?
Google’s search engine is very complex. An in-depth look at how Google finds, stores, and prioritizes pages remains beyond the scope of this article.
At a high level Google works hard finding (or crawling) as many useful pages as possible. Plus, Google works hard storing (or indexing) those pages that return relevant searches. Additionally, the Google index works hard on returning the proper pages that best satisfies a searcher’s search query. (As a side effect, this likely helps Alphabet’s bottom line as well, but that’s another discussion).
Again at a high (and oversimplified) level you want:
- the good stuff indexed (the pages on your site that are high quality, useful for searchers and likely drive desirable actions for your business).
- the bad stuff out of the Google index (pages that are low value and/or are thin or duplicated that hurt you more than help you in driving relevant traffic to your site).
Another thing to note: indexation is not necessarily the same thing as what shows up in search results. Google maintains an index of pages internally. When you search Google.com for topics, you see some of your pages. That is not necessarily all of the pages Google keeps in its index. Indexed pages may never actually show in search results or get clicks and come to your site.
The rest of this article focuses on analyzing what pages from your site are in the index as well as what you – as a marketer – can do to take control and better optimize what is and isn’t indexed. Additionally, a number of resources exist for learning more about how Google indexing works, including:
- Moz’s walk-through of how search engines operate.
- A couple of different break-downs of a Google Search Engineer’s presentation on how the Google index works.
- This visual representation of How Google Works.
Understanding Index Stats
For many, the index statistics you see about your own site yields some pretty confusing thoughts. Google offers two common ways that show your site statistics about how many pages on your site Google indexes.
Index Stats on Google.com
In order to see how many and which of your pages become indexed in Google, start by actually going to Google.com and typing site:yoursite.com. Let’s look at what Google shows in the site search operator for a site, which we wrote about in the past, SearchEngineLand.com:
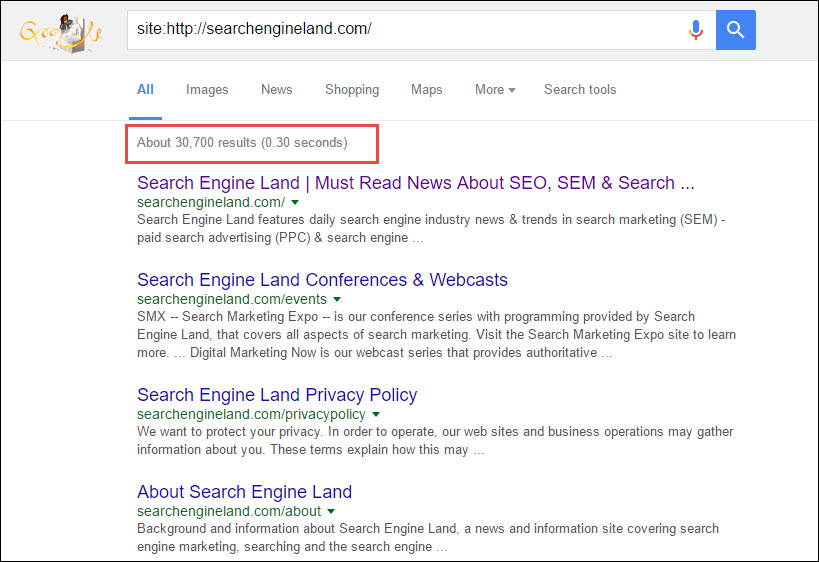
About 30,700 results – that’s quite a few! If this were your site and you checked your index stats for the first time you likely have two emotions. First, excitement as you think lots of my posts are being indexed! Conversely, you might feel some alarm as you think realize your site doesn’t contain that many pages.
As you start to dig through the pages that are indexed and click through to additional pages of results (ten – or far fewer with ads and other featured Google content dominating a lot of SERPs – is the default of course, but as I’m frequently digging through SERPs I like to change my results per page to 100) something pretty odd happens. With my settings at 100 results per page when I scroll to the bottom of the search result for SEL’s site search I see 8 links:
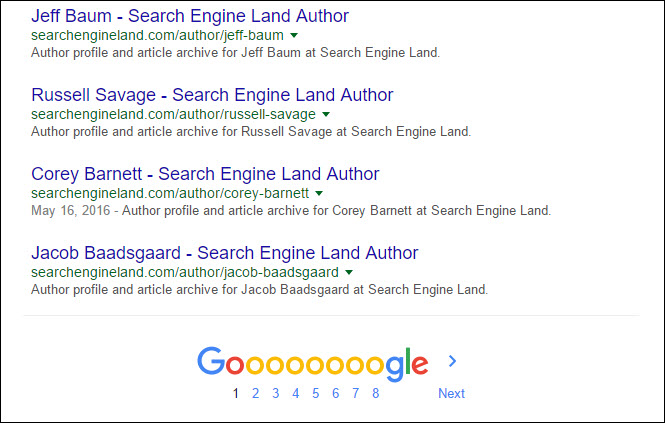
8 x 100 results clearly does not equal “About 30,700.” Odd: I thought Google provided over 30,000 results. If I click the link to the 8th page of results yield even more confusing:
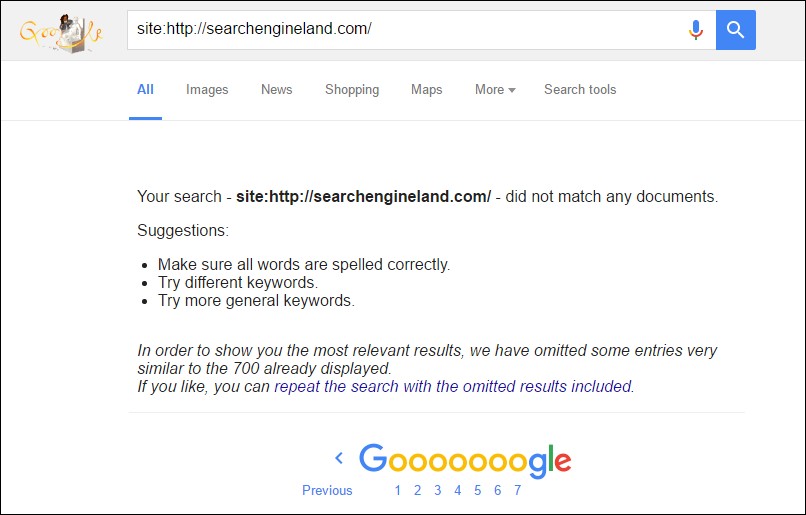
And if I click the “repeat the search with the omitted results included” link and click back through to the last page I see something similar.
But Search Engine Land is an extremely trusted site that posts several new pieces of content a day. So that can’t be all of the pages Google has indexed, right?
It’s definitely not. Google has actually been seen testing dropping this altogether. Plus, Google explicitly said these numbers are not to be completely trusted for several years (that video is from 2010!). And this problem gets worse the larger your site gets:
DYK the “number of results” you see in search results is really just an approximation that’s less accurate the more potential results exist? pic.twitter.com/o2odhwjsIA
— Gary Illyes ᕕ( ᐛ )ᕗ (@methode) February 11, 2017
Where else can we find our indexation counts? Or how can we understand which pages on our site are indexed?
Index Stats in Google Search Console (Formerly Webmaster Tools)
Your Google Search Console account provides additional data about your site index results. And if you don’t have a GSC account, then set one up here today.
For our overview, let’s look at the account for a site that my company owns. There’s an entire sub-section of Google Search Console dedicated to Google Index data.
Index Status in Google Search Console
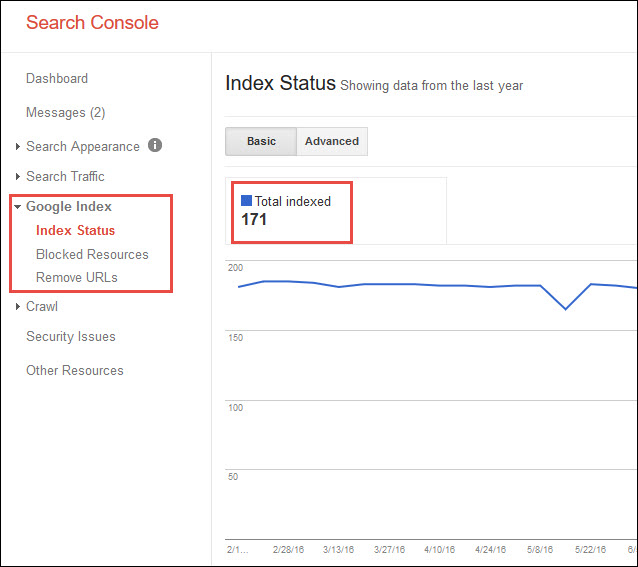
GSC data generally provides more accurate information. Plus, it offers some trend data as well. But, what if you see a number of indexed pages that seems way too low? Or dramatically under-reported Search Analytics stats?
Typically, these issues occur based on how Google Search Console deals with sub-domains, www and non-www versions of your site, and http and https versions of your site.
If your Google Search Console numbers are extremely low, check the very specific URL associated with the site in the top navigation:
Additionally, if you moved your site over to https or utilize a subdomain (eg http://info.measuredsem.com), add those as separate sites. Also, if you switched from http://www.measuredsem.com to http://measuredsem.com or support both, then set your preferred domain within your account.
Additionally there’s another place you can get information about how your site is indexed within Google Search Console.
Sitemaps in Google Search Console
Google Search Console includes a sitemap section, which enables an XML sitemap submission for your site. Also, this section offers a sense of how many of the pages submitted are actually in the index. Plus, the section shows how that number changes over time.
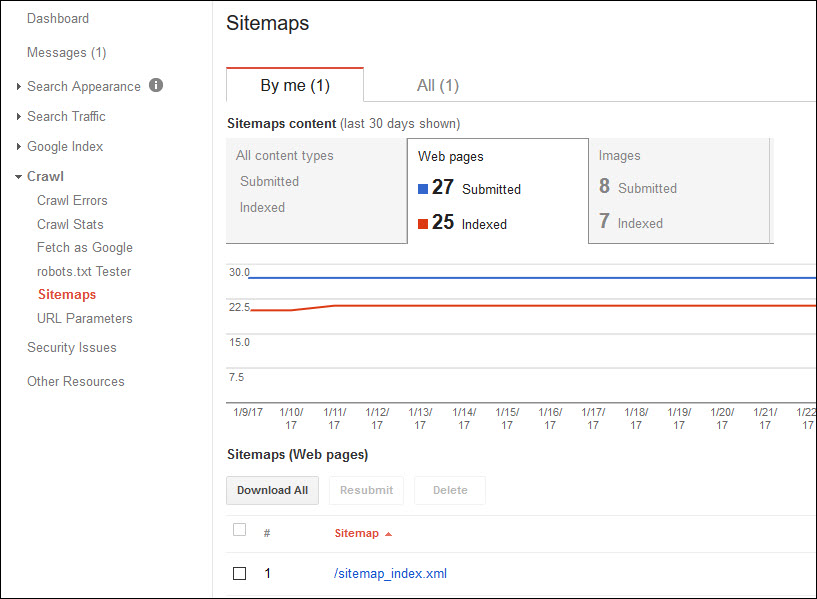
The challenge here is that while you can look within your XML sitemap to see which pages you’ve submitted, you don’t necessarily have the level of detail you may want to answer specific questions (like whether large swaths of pages are or aren’t indexed).
5 Actionable Google Indexation Tips
So now you know a bit more about how Google’s index works. Plus, some of the tools you that shows how your site performs within the Google index. What about actually solving specific index-related issues? Based on my work with clients and some research around the topic, here are the five biggest questions / issues I’ve found in relation to Google indexation:
1. How to tell which specific pages are NOT indexed
Pages that are not in Google’s index won’t show up in search results. So one of the first things you may want to figure out is “which pages on my site aren’t indexed?” Unfortunately, most of the methods listed above lack a solution for this problem. The previous methods help understand the pages on your site in the Google index. However, those methods do not address the pages on your site not in the Google index. For a very small site, this may be pretty easy to spot. But if you maintain an active blog, your site likely contains enough pages that “eyeballing” missing pages isn’t a reasonable option. Two main tools address this process:
Step One: Crawl Your Site with Screaming Frog
Screaming Frog is generally one of my most used apps through any SEO site audit process. In this screenshot, it provides a picture of what pages are present on your site:
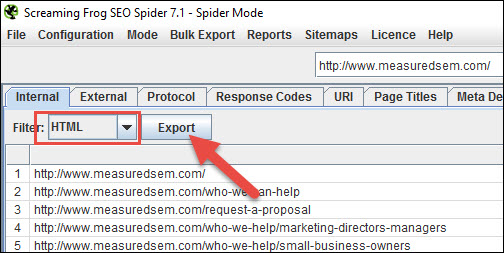
Screaming Frog is a super useful / powerful SEO tool, but for our purposes here we just want to crawl the site and filter for HTML pages. Then, filter that list for any of the pages on our site that we want in the index. We’ll get to dealing with pages we don’t want in a minute.
From there, I’ll use another tool that’s incredibly helpful in any technical SEO audit: URL Profiler.
URL Profiler is another extremely powerful SEO tool, but again here we’re going to use it for a pretty narrow purpose. Finding out which of the URLs on our site (which we just exported from our crawl) are actually indexed:
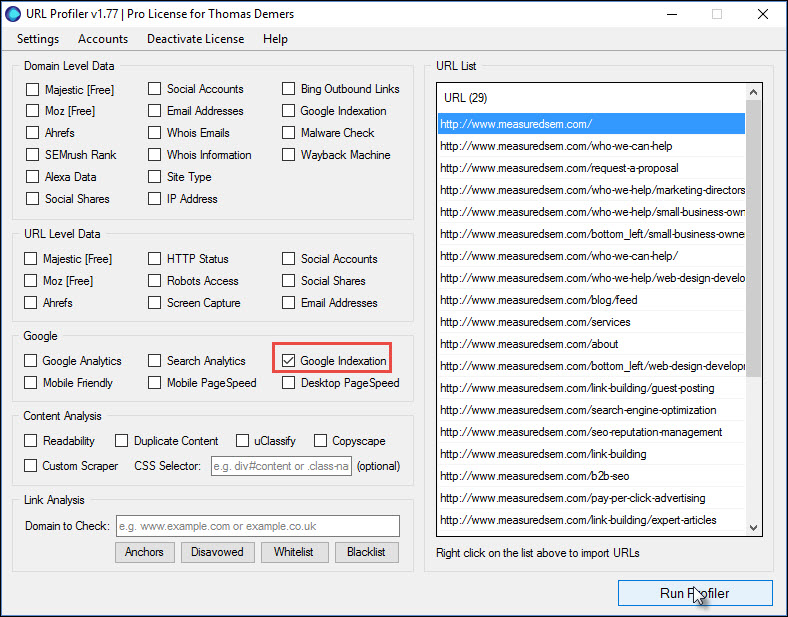
If you have a larger site, this typically requires some proxies to check indexation. If you’re not overly technical it sounds intimidating, but it’s incredibly easy. It takes a few minutes and requires no technical expertise whatsoever (beyond copy/paste skills).
Occasionally, it takes a couple of times and always leave some time for larger crawls. But, eventually you end up with a list of all of the pages that are not indexed on your site.
2. How to get something (your whole site, a new page, an existing page that’s not indexed) indexed
Getting a new site indexed used to be an industry to itself. However, these days, if you own a legit website and business, the process is streamlined. In fact, your home page and overall domain should be indexed very quickly. For example, sending out a Tweet with a link help Google index the site. Or receiving a link from another site works. Finally, simply submitting your URL to Google for free works! As a result, many sites with no content and no external links / tweets / etc. get indexed without any effort. Recently my company bought 50 domains and put up very simple place holder pages on each. Google indexed 28 of them before we conducted any kind of promotion at all.
For existing sites with a set of pages needing indexing, take a look at your options.
A. Fetch & Submit to Index Via Google Search Console
For sites with a small number of URLs, submit them each to Google Console for indexation. This is a fairly simple process. Start by logging into your Google Search Console account and looking at the left navigation under crawl and clicking into Fetch as Google:
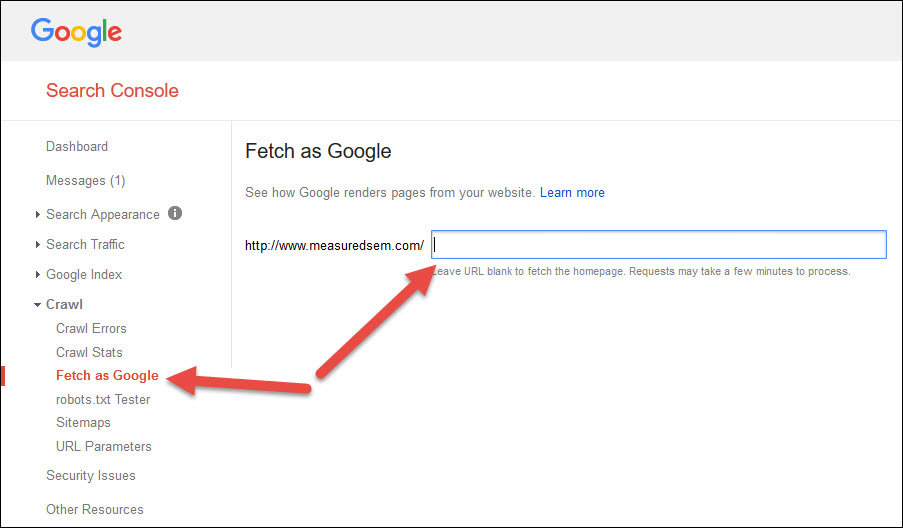
Next, you enter the URL that needs submission and click fetch. You’ll be given the option to request indexing:
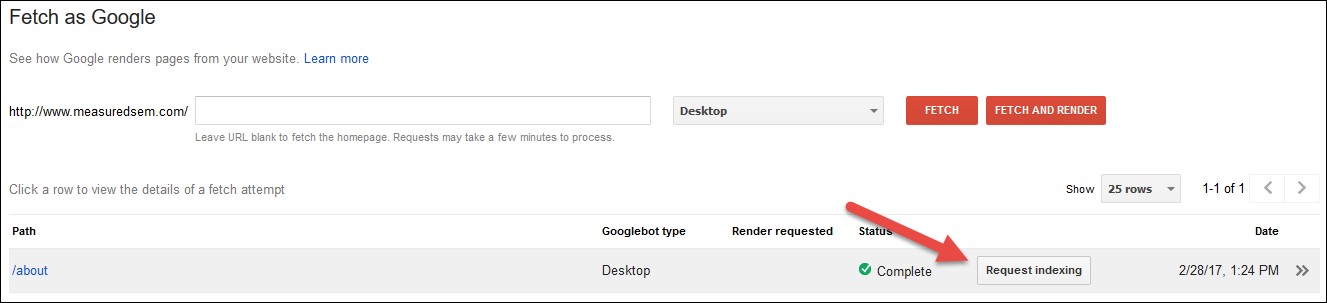
Finally you submit either the URL itself or the URL and those linked to from the page. For our purposes, since we have a specific set of URLs we’d like to see indexed (and because we have a limited number of submissions – 500 single URLs and only 10 multiple URL submissions – per month) we’ll submit the URL to the index:
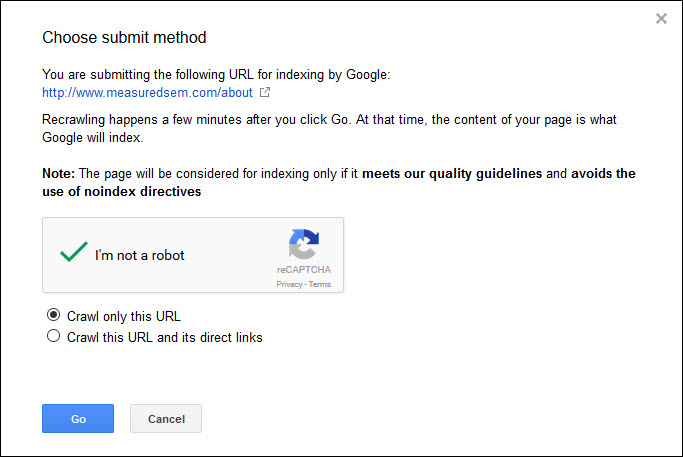
Lastly you should see that your indexing request went through:
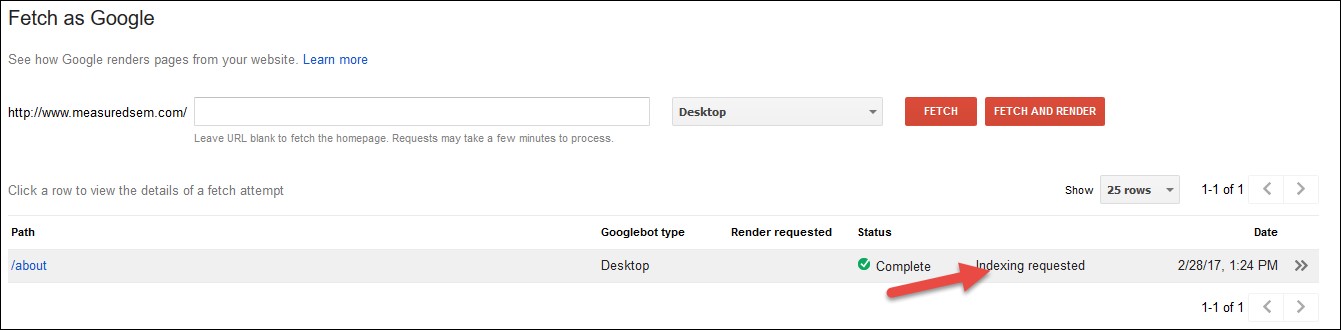
If you’re working through a list of URLs, you can then give it a couple of days and run the same list through URL Profiler again and see how your efforts impacted indexation.
B. Share Your URLs Socially
Sharing your URLs and content via social networks also improves indexation of key pages. For example, for valuable pages (and related to your core audience), share them socially. In particular, this works for sites with popular social accounts.
For instance does your site contains a swath of product pages detailing specific features? If so, queue up 1 tweet a week / every couple of days sharing a specific feature page. Something like “Did you know {product} could help with {thing feature helps with}? {link}” works well.
C. Fix the Underlying Issues!
Does your site still contain large volumes of pages that need indexation? If so, then likely have a foundational SEO issue with your site. You’ll want to investigate:
- Link Equity – Do you have more pages on your site than the link equity (number and authority of links pointed to your site) can support? This may mean that deeper pages aren’t going to be crawled and indexed until you find ways to build links to your domains (and potentially find ways to get links and shares for your deeper pages).
- Site Architecture – Your site’s information architecture is a topic that’s beyond the scope of this article. But you may have pages that are several clicks from your site’s home page. As a result, these are difficult for search engines to reach. Again this is something to investigate (and/or potentially hire an experienced SEO to investigate).
- Sitemap – Finally, if you haven’t already submit a dynamic XML sitemap to Google Search Console. This step drives better indexation of your site.
3. How to Keep Pages You Don’t Want Indexed Out of the Index
Another common issue for marketers is that you want to keep a specific page out of Google’s index. Maybe it’s a duplicate of an existing page, a very thin page that has some use to users but wouldn’t for searchers, or possibly it’s something with private information you don’t want in Google’s index.
Whatever the reason, there are a few core methods for keeping content out of Google’s index.
1. Meta No Index Tag
In many instances the preferred method of keeping a page out of Google’s index is to add a Meta No Index tag, from Google’s documentation on the subject:
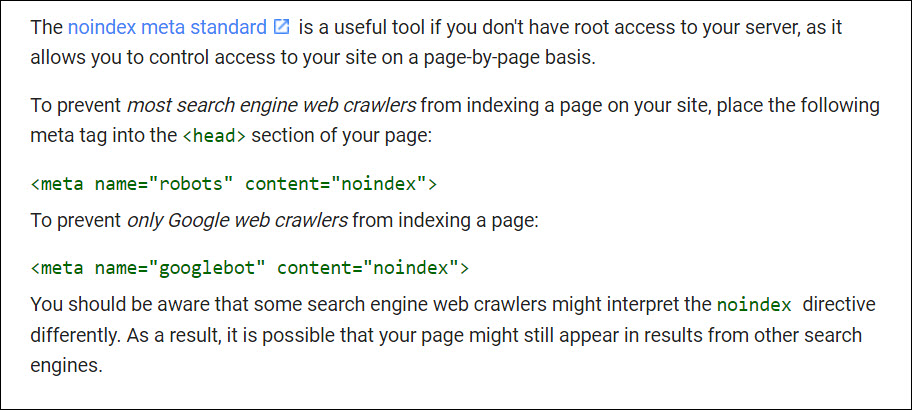
The no index tag offers a great solution. It instructs Google to remove pages from the index. For example, sites with content already indexed, the no index tag offer a preferred method of deindexing your content. The robots disallow directive keeps Google from crawling the page. But will not necessarily remove it from the index if it’s already there.
Conversely as Google engineer Gary Illyes points out:
DYK blocking a page with both a robots.txt disallow & a noindex in the page doesn’t make much sense cos Googlebot can’t “see” the noindex? pic.twitter.com/N4639rCCWt
— Gary Illyes ᕕ( ᐛ )ᕗ (@methode) February 10, 2017
Google must be able to crawl your page to remove it from the index via this method. So ensure the pages remain accessible wait until its crawled (or Fetch as Google to request it be crawled / reconsidered).
2. Robots.txt Disallow
For new sites (or site sections) awaiting indexation,use the robots disallow directive. For instance a staging site, or subdomain under construction and not ready for primetime likely need this option.
Again adding this directive does not necessarily cause your content to be removed from the index if its already appearing there. In fact it can lead to a result that’s indexed and just has a suboptimal description.
An important warning with use of disallow is to be sure not to disallow more than you intended. Be careful not to block subsections of your site where there may be valuable content you want searchers to be able to access. And test changes within your robots file in Google Search Console with the robot tester tool.
Removing URLs & Excluding URL Parameters via Search Console
Finally, if you have parameters that are being added by your site’s content management system (maybe because of filtered search results, pagination, or similar) that are being indexed that you’d like removed, you can also give Google more information about those parameters or request that specific URLs be removed by removing URLs temporarily from search results (not necessarily from Google’s index, and not necessarily permanently):
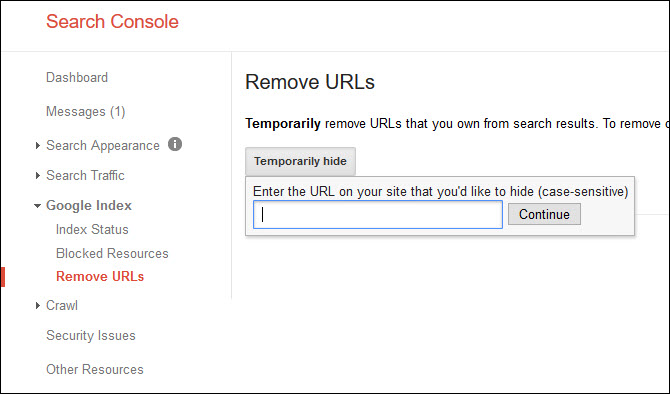
Additionally, this provides a handy methodology for bulk removing URLs from search results or identifying a specific parameter:
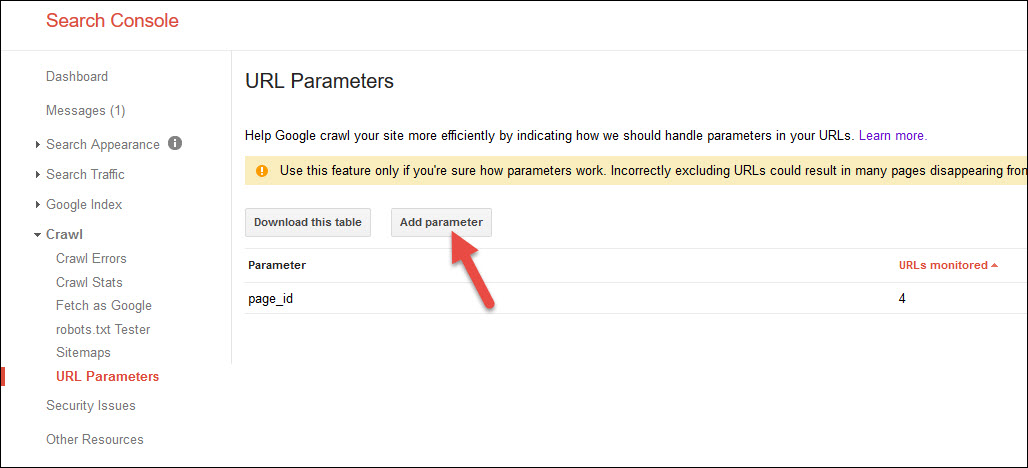
And then giving Google more information about it:
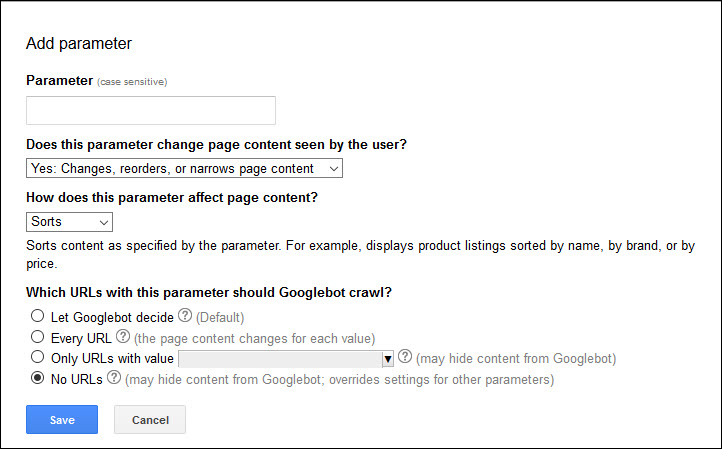
Google’s John Mueller said that this functions similarly to “permanently” noindexing content. So this offers a viable option for one-off URLs. Ideally, though, in most cases rather than leverage a temporary removal you’ll want to dig in and address the core issues. What is it about the technical structure of your site that’s creating the need for pages to be deindexed? Why are you (or are you) suffering from “index bloat” in the first place?
4. What is “Index Bloat” and How Do I Fix It?
Index bloat is effectively when you have unnecessary pages indexed by Google that are not likely to drive relevant traffic to your site in response to users’ queries. This creates an issue because it forces search engines to spend time crawling and indexing low value pages (which could use up your “crawl budget”). Plus, potentially serves low-value pages in some search results (leading to a poor user experience and poor engagement metrics). Containing a lot of thin or largely duplicated content with terrible engagement metrics likely causes a lower quality ranking in Google’s eyes.
In addition to using the tools and processes above to analyze which pages are and aren’t currently in the index, then using more of them to remove lower quality and lower value pages from the index, here are two great resources on the topic:
- Green Lane SEO’s guide to find and fix index bloat issues
- Portent Interactive’s quick & dirty index diagnostics
Here again an important note is not to “cut too deep.” Before you start to whack large sections of your site from Google’s index, look in Analytics (or grab the URLs and run them through URL Profiler) to make sure you’re not cutting off traffic and leads / sales from these pages.
5. What Tools Can Help with Monitoring Indexation (ie what are the best “Google Index Checkers?”)
As I’ve mentioned ad nauseum here my personal preference is to leverage URL Profiler as a Google Index Checker, but here are some additional options:
- http://indexchecking.com/
- https://northcutt.com/tools/free-seo-tools/google-indexed-pages-checker/
- https://www.greenlaneseo.com/blog/google-indexation-tester/
BONUS: Mobile Indexation Resources
Mobile & app indexation specifically can be slightly different beasts than traditional indexation, so if you’re experiencing issues there here are some additional mobile-focused indexation resources:
- https://www.apptentive.com/blog/2015/12/15/app-indexing-how-to-index-your-app-on-google/
- https://www.bruceclay.com/blog/apps-101-what-is-deep-linking-and-app-indexing-setup/
- https://www.slideshare.net/justinrbriggs/how-to-setup-app-indexation
- http://searchengineland.com/5-tips-for-optimal-mobile-site-indexing-107088
- https://www.deepcrawl.com/blog/best-practice/app-deep-linking-for-beginners-google-app-indexing-facebook-app-links/
- https://moz.com/blog/how-to-get-your-app-content-indexed-by-google
What did we miss? What other Google indexation issues have you seen / what tips can you share?



{kind=link}